
Efficient NLP
The KV Cache: Memory Usage in Transformers
1 year ago - 8:33

Arize AI
KV Cache Explained
8 months ago - 4:08

USENIX
FAST '25 - Mooncake: Trading More Storage for Less Computation — A KVCache-centric Architecture...
2 months ago - 17:17

Umar Jamil
LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLU
1 year ago - 1:10:55

Julien Simon
Deep Dive: Optimizing LLM inference
1 year ago - 36:12

YanAITalk
LLM inference optimization: Architecture, KV cache and Flash attention
9 months ago - 44:06

NVIDIA Developer
Distributed Inference 101: Managing KV Cache to Speed Up Inference Latency
3 months ago - 5:29

Xiaol.x
LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification
2 days ago - 17:09
![[REFAI Seminar 05/02/25 ] A Case for KV Cache Layer: Enabling the Next Phase of Fast Distributed LLM](/vi/Y-qLjQbT_xw/mqdefault.jpg)
Rutgers Efficient AI Seminar
[REFAI Seminar 05/02/25 ] A Case for KV Cache Layer: Enabling the Next Phase of Fast Distributed LLM
3 weeks ago - 1:04:04

Discover AI
Goodbye RAG - Smarter CAG w/ KV Cache Optimization
6 months ago - 26:19

Vizuara
Key Value Cache from Scratch: The good side and the bad side
2 months ago - 59:42

Kian
KV Cache Explained
4 months ago - 13:21

Tensordroid
Key Value Cache in Large Language Models Explained
1 year ago - 17:36

AI Paper Podcasts
xKV: Cross-Layer SVD for KV-Cache Compression (Mar 2025)
2 months ago - 25:57

Lex Clips
How to make LLMs fast: KV Caching, Speculative Decoding, and Multi-Query Attention | Cursor Team
8 months ago - 15:15
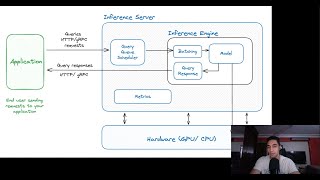
Ahmed Tremo
How to Efficiently Serve an LLM?
10 months ago - 12:13
![How DeepSeek Rewrote the Transformer [MLA]](/vi/0VLAoVGf_74/mqdefault.jpg)
Welch Labs
How DeepSeek Rewrote the Transformer [MLA]
3 months ago - 18:09

Neural Magic
vLLM Office Hours - Disaggregated Prefill and KV Cache Storage in vLLM - November 14, 2024
7 months ago - 48:06

The ML Tech Lead!
How To Reduce LLM Decoding Time With KV-Caching!
7 months ago - 12:13

Umar Jamil
Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNorm
1 year ago - 3:04:11

Arxflix
SnapKV: Transforming LLM Efficiency with Intelligent KV Cache Compression!
1 year ago - 3:27

Pliops
GenAI LLM KV Cache Offloading - Pliops CTO Lecture
4 months ago - 46:51

ACM SIGCOMM
SIGCOMM'24 TS1: CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving
5 months ago - 19:50

EasyAI Hub
You Won't Believe How KV Cache Changes AI Processing - Advanced Attention Mechanism
1 month ago - 7:39
![[QA] RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression](/vi/p7IB_D-WwpU/mqdefault.jpg)
Arxiv Papers
[QA] RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
4 months ago - 7:48

CodeGPT
Goodbye rag smarter cag w kv cache optimization
4 weeks ago - 1:15

Giuseppe Canale
Optimizing Transformer Models with KV Cache and Trie Indexing
6 months ago - 2:09

Huawei IT Products & Solutions
#HWIDI 2025-Optimizing Scalable LLM Inference-System Strategies for Proactive KV Cache Mgmt-Chen Lei
1 month ago - 22:52

NDSS Symposium
NDSS 2025 - I Know What You Asked: Prompt Leakage via KV-Cache Sharing in Multi-Tenant LLM Serving
1 month ago - 16:22

Arize AI
Accurate KV Cache Quantization with Outlier Tokens Tracing
1 month ago - 25:47

AI, Math and Beyond
How KV Caching Speeds Up LLMs like ChatGPT #aiexplained
2 months ago - 11:27

Vizuara
Multi-Query Attention Explained | Dealing with KV Cache Memory Issues Part 1
2 months ago - 37:44

SkillCurb
Replace LLM RAG with CAG KV Cache Optimization (Installation)
5 months ago - 7:04

AINewsMediaNetwork
🚀 NVIDIA’s New KV Cache Optimizations in TensorRT-LLM – AI Just Got Smarter! 🚀
4 months ago - 2:58

vishal
HuggingFace's Default KV Cache and the flash_attn_varlen_func Docstring
3 weeks ago - 1:07:53
![[MLArchSys 2025]|SafeKV: Safe KV-Cache Sharing in LLM Serving](/vi/SJqN4HY1HKQ/mqdefault.jpg)
kexin.chu2017
[MLArchSys 2025]|SafeKV: Safe KV-Cache Sharing in LLM Serving
3 weeks ago - 11:27

Qiao Xiang
SIGCOMM Paper Reading Group - Episode 6 (KV Cache Compression and Streaming)
1 month ago - 1:03:55


